TensorFlow VGG16网络实现Cifar |
您所在的位置:网站首页 › tensorflow cifar10分类 › TensorFlow VGG16网络实现Cifar |
TensorFlow VGG16网络实现Cifar
|
这次继续在colab中实现TensorFlow学习的第二个任务:对cifar-10数据集进行图像分类任务的学习。本文采用了VGG-16网路结构,去掉了一层max pooling层,最终测试集上可以达到0.92左右的结果。 cifar-10数据集介绍CIFAR-10数据集包含10个类别的RGB彩色图片。图片尺寸为32×32,这十个类别包括:飞机、汽车、鸟、猫、鹿、狗、蛙、马、船、卡车。一共有50000张训练图片和10000张测试图片。 首先来实现数据集的处理。 下载cifar10 Python版的数据文件并解压,数据文件共有6个data_batch_1 ~ data_batch_5,以及test_batch,每个文件含有10000张图片。 读取数据集得到一个很大的Dictionary,有dict_keys([‘batch_label’, ‘labels’, ‘data’, ‘filenames’])五个关键字,我们关心其中的两项。labels-标签,data-数据。label是100001的数字,每一个标签为0-9的数字。data是100003072的数组,每个图片是32 * 32 * 3的大小。 将data数据转换从图片数组的时候要注意,data中3072个记录,前1024个条目包含红色通道值,下一个1024个绿色,最后1024个蓝色。图像以行优先顺序存储,以便数组的前32个条目是图像第一行的红色通道值。所以进行reshape时要先reshape成(-1,3,32,32)的向量,然后transpose(0,2,3,1)将其转化为我们需要(-1,32,32,3)的向量。 加载数据集并打印其中三张图片 import pickle import matplotlib.pyplot as plt def load_file(filename): with open(filename, 'rb') as fo: data = pickle.load(fo, encoding='latin1') return data data = load_file('./cifar-10-batches-py/data_batch_1') print(data.keys()) image_data = data['data'] labels = data['labels'] label_count = len(labels) print(image_data.shape) picture_data = image_data.reshape(-1,3,32,32) picture_data = picture_data.transpose(0,2,3,1) print(picture_data.shape) plt.subplot(131) plt.imshow(picture_data[1]) plt.subplot(132) plt.imshow(picture_data[2]) plt.subplot(133) plt.imshow(picture_data[3]) 导入包 预先设置
导入包 预先设置
实验环境google colab,加速方式GPU加速,全部实现分3个step。 step-1: 导入需要的包,设定参数 import tensorflow as tf import numpy as np import time import random import pickle import math import datetime from keras.preprocessing.image import ImageDataGenerator #预先定义的变量 class_num = 10 image_size = 32 img_channels = 3 iterations = 200 batch_size = 250 weight_decay = 0.0003 dropout_rate = 0.5 momentum_rate = 0.9 data_dir = './cifar-10-batches-py/' log_save_path = './vgg_16_logs' model_save_path = './model/' 数据处理这一部分将实现加载数据并处理成可输入神经网络进行训练的格式。 data数据转化为(-1,32,32,3)的格式 ,并进行归一化处理。labels数据转化为(-1,10)的格式。step-2: 读取数据,得到train_data, train_labels, test_data, test_labels #========数据处理========= #读文件 def unpickle(file): with open(file, 'rb') as fo: dict = pickle.load(fo, encoding='latin1') return dict #从读入的文件中获取图片数据(data)和标签信息(labels) def load_data_one(file): batch = unpickle(file) data = batch['data'] labels = batch['labels'] print("Loading %s : img num %d." % (file, len(data))) return data, labels #将从文件中获取的信息进行处理,得到可以输入到神经网络中的数据。 def load_data(files, data_dir, label_count): global image_size, img_channels data, labels = load_data_one(data_dir + files[0]) for f in files[1:]: data_n, labels_n = load_data_one(data_dir + '/' + f) data = np.append(data, data_n, axis=0) labels = np.append(labels, labels_n, axis=0) #标签labels从0-9的数字转化为float类型(-1,10)的标签矩阵 labels = np.array([[float(i == label) for i in range(label_count)] for label in labels]) #将图片数据从(-1,3072)转化为(-1,3,32,32) data = data.reshape([-1, img_channels, image_size, image_size]) #将(-1,3,32,32)转化为(-1,32,32,3)的图片标准输入 data = data.transpose([0, 2, 3, 1]) #data数据归一化 data = data.astype('float32') data[:, :, :, 0] = (data[:, :, :, 0] - np.mean(data[:, :, :, 0])) / np.std(data[:, :, :, 0]) data[:, :, :, 1] = (data[:, :, :, 1] - np.mean(data[:, :, :, 1])) / np.std(data[:, :, :, 1]) data[:, :, :, 2] = (data[:, :, :, 2] - np.mean(data[:, :, :, 2])) / np.std(data[:, :, :, 2]) return data, labels def prepare_data(): print("======Loading data======") image_dim = image_size * image_size * img_channels meta = unpickle(data_dir + 'batches.meta') print(meta) label_names = meta['label_names'] #依次读取data_batch_1-5的内容 train_files = ['data_batch_%d' % d for d in range(1, 6)] train_data, train_labels = load_data(train_files, data_dir, class_num) test_data, test_labels = load_data(['test_batch'], data_dir, class_num) print("Train data:", np.shape(train_data), np.shape(train_labels)) print("Test data :", np.shape(test_data), np.shape(test_labels)) print("======Load finished======") #重新打乱训练集的顺序 indices = np.random.permutation(len(train_data)) train_data = train_data[indices] train_labels = train_labels[indices] print("======数据准备结束======") return train_data, train_labels, test_data, test_labels train_x, train_y, test_x, test_y = prepare_data() VGG-16网络
VGG-16网络
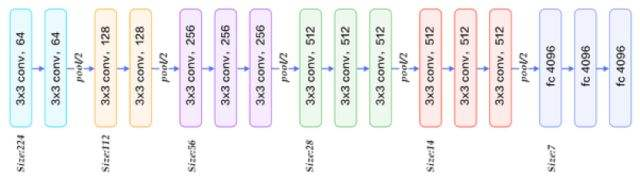
VGG-16网络结构如下: VGG-16标准输入是224 * 224,经过5次max pooling和13次卷积后变成7 * 7 * 512,cifar10数据集的图片大小只有32 * 32,所以少进行一次max pooling,最后得到2 * 2 *512的结果传入全连接层。 卷积网络增加了batch normalization。参数初始化采用了he_normal()的方法。 梯度下降采用了adam学习率自适应的优化算法。alpha参数初始值为0.001,训练集精度达到0.97以上后alpha变为0.0001,精度达到0.996以上alpha变为0.00001 。 为了防止过拟合,添加了dropout和L2正则化。 设置迭代次数为40,epcho达到25之后精度基本不再提升。最终train_loss: 0.0319, train_acc: 0.9964, test_loss: 0.5629, test_acc: 0.8680 step-3: 设计网络,开始训练 #=========网络设计========= #初始化权重,采用正则化随机初始,加入少量的噪声来打破对称性以及避免0梯度 def weight_variable(name, sp): initial = tf.initializers.he_normal() #initial = tf.truncated_normal(shape, mean=0.0, stddev=0.05, dtype=tf.float32) return tf.get_variable(name = name, shape = sp, initializer = initial) #return tf.Variable(initial) def bias_variable(shape): initial = tf.constant(0.1, shape=shape) return tf.Variable(initial) def batch_norm(input): return tf.contrib.layers.batch_norm(input, decay=0.9, center=True, scale=True, epsilon=1e-3, is_training=train_flag, updates_collections=None) def conv(name,x,w,b): #去掉BN #return tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(x,w,strides=[1,1,1,1],padding='SAME'),b),name=name) return tf.nn.relu(batch_norm(tf.nn.bias_add(tf.nn.conv2d(x,w,strides=[1,1,1,1],padding='SAME'),b)),name=name) def max_pool(name,x,k): return tf.nn.max_pool(x,ksize=[1,k,k,1],strides=[1,k,k,1],padding='SAME',name=name) def fc(name,x,w,b): return tf.nn.relu(batch_norm(tf.matmul(x,w)+b),name=name) #VGG-16网络,因为输入尺寸小,去掉最后两个个max pooling层 def vgg_net(_X,_weights,_biases,keep_prob): conv1_1=conv('conv1_1',_X,_weights['wc1_1'],_biases['bc1_1']) conv1_2=conv('conv1_2',conv1_1,_weights['wc1_2'],_biases['bc1_2']) pool1=max_pool('pool1',conv1_2,k=2) conv2_1=conv('conv2_1',pool1,_weights['wc2_1'],_biases['bc2_1']) conv2_2=conv('conv2_2',conv2_1,_weights['wc2_2'],_biases['bc2_2']) pool2=max_pool('pool2',conv2_2,k=2) conv3_1=conv('conv3_1',pool2,_weights['wc3_1'],_biases['bc3_1']) conv3_2=conv('conv3_2',conv3_1,_weights['wc3_2'],_biases['bc3_2']) conv3_3=conv('conv3_3',conv3_2,_weights['wc3_3'],_biases['bc3_3']) pool3=max_pool('pool3',conv3_3,k=2) conv4_1=conv('conv4_1',pool3,_weights['wc4_1'],_biases['bc4_1']) conv4_2=conv('conv4_2',conv4_1,_weights['wc4_2'],_biases['bc4_2']) conv4_3=conv('conv4_3',conv4_2,_weights['wc4_3'],_biases['bc4_3']) pool4=max_pool('pool4',conv4_3,k=2) conv5_1=conv('conv5_1',pool4,_weights['wc5_1'],_biases['bc5_1']) conv5_2=conv('conv5_2',conv5_1,_weights['wc5_2'],_biases['bc5_2']) conv5_3=conv('conv5_3',conv5_2,_weights['wc5_3'],_biases['bc5_3']) pool5=max_pool('pool5',conv5_3,k=1) _shape=pool5.get_shape() flatten=_shape[1].value*_shape[2].value*_shape[3].value pool5=tf.reshape(pool5,shape=[-1,flatten]) fc1=fc('fc1',pool5,_weights['fc1'],_biases['fb1']) fc1=tf.nn.dropout(fc1,keep_prob) fc2=fc('fc2',fc1,_weights['fc2'],_biases['fb2']) fc2=tf.nn.dropout(fc2,keep_prob) output=fc('fc3',fc2,_weights['fc3'],_biases['fb3']) #fc3=tf.nn.dropout(fc3,keep_prob) return output weights={ 'wc1_1' : weight_variable('wc1_1', [3,3,3,64]), 'wc1_2' : weight_variable('wc1_2', [3,3,64,64]), 'wc2_1' : weight_variable('wc2_1', [3,3,64,128]), 'wc2_2' : weight_variable('wc2_2', [3,3,128,128]), 'wc3_1' : weight_variable('wc3_1', [3,3,128,256]), 'wc3_2' : weight_variable('wc3_2', [3,3,256,256]), 'wc3_3' : weight_variable('wc3_3', [3,3,256,256]), 'wc4_1' : weight_variable('wc4_1', [3,3,256,512]), 'wc4_2' : weight_variable('wc4_2', [3,3,512,512]), 'wc4_3' : weight_variable('wc4_3', [3,3,512,512]), 'wc5_1' : weight_variable('wc5_1', [3,3,512,512]), 'wc5_2' : weight_variable('wc5_2', [3,3,512,512]), 'wc5_3' : weight_variable('wc5_3', [3,3,512,512]), 'fc1' : weight_variable('fc1', [2*2*512,4096]), 'fc2' : weight_variable('fc2', [4096,4096]), 'fc3' : weight_variable('fc3', [4096,10]) } biases={ 'bc1_1' : bias_variable([64]), 'bc1_2' : bias_variable([64]), 'bc2_1' : bias_variable([128]), 'bc2_2' : bias_variable([128]), 'bc3_1' : bias_variable([256]), 'bc3_2' : bias_variable([256]), 'bc3_3' : bias_variable([256]), 'bc4_1' : bias_variable([512]), 'bc4_2' : bias_variable([512]), 'bc4_3' : bias_variable([512]), 'bc5_1' : bias_variable([512]), 'bc5_2' : bias_variable([512]), 'bc5_3' : bias_variable([512]), 'fb1' : bias_variable([4096]), 'fb2' : bias_variable([4096]), 'fb3' : bias_variable([10]), } #数据增强 def _random_crop(batch, crop_shape, padding=None): oshape = np.shape(batch[0]) if padding: oshape = (oshape[0] + 2*padding, oshape[1] + 2*padding) new_batch = [] npad = ((padding, padding), (padding, padding), (0, 0)) for i in range(len(batch)): new_batch.append(batch[i]) if padding: new_batch[i] = np.lib.pad(batch[i], pad_width=npad, mode='constant', constant_values=0) nh = random.randint(0, oshape[0] - crop_shape[0]) nw = random.randint(0, oshape[1] - crop_shape[1]) new_batch[i] = new_batch[i][nh:nh + crop_shape[0], nw:nw + crop_shape[1]] return new_batch def _random_flip_leftright(batch): for i in range(len(batch)): if bool(random.getrandbits(1)): batch[i] = np.fliplr(batch[i]) return batch def data_augmentation(batch): batch = _random_flip_leftright(batch) batch = _random_crop(batch, [32, 32], 4) return batch #测试集跑模型,记录精度和损失 def run_test(sess): acc = 0.0 loss = 0.0 pre_index = 0 #数据量大,采用类似minibatch的方法,分批次测试,在将其汇总 add = 1000 for it in range(10): batch_x = test_x[pre_index : pre_index+add] batch_y = test_y[pre_index : pre_index+add] pre_index = pre_index + add loss_, acc_ = sess.run([cross_entropy, accuracy],feed_dict={x: batch_x, y_: batch_y, keep_prob: 1.0, train_flag : False}) loss += loss_ / 10.0 acc += acc_ / 10.0 summary = tf.Summary(value=[tf.Summary.Value(tag="test_loss", simple_value=loss), tf.Summary.Value(tag="test_accuracy", simple_value=acc)]) return acc, loss, summary #训练训练集完所有50000张图片的过程 #采用mini-batch梯度的方法,batch_size=250, iterations=200 #一个epcho的精度和损失是200个iterations精度和损失的均值 def train_epcho(sess, epcho): pre_index = 0 acc = 0.0 loss = 0.0 for it in range(1, iterations+1): batch_x = train_x[pre_index : pre_index+batch_size] batch_y = train_y[pre_index : pre_index+batch_size] #使用数据增强策略 batch_x = data_augmentation(batch_x) _, batch_loss = sess.run([train_step, cross_entropy], feed_dict={x: batch_x, y_: batch_y, keep_prob: dropout_rate, train_flag : True, learning_rate: alpha}) batch_acc = accuracy.eval(feed_dict={x: batch_x, y_: batch_y, keep_prob: 1.0, train_flag : True}) loss += batch_loss acc += batch_acc pre_index += batch_size if it%20 == 0: print("epcho: %d, iterations: %d, loss: %.4f, acc: %.4f"%(epcho, it, batch_loss, batch_acc)) loss /= iterations acc /= iterations summary = tf.Summary(value=[tf.Summary.Value(tag="train_loss", simple_value=loss), tf.Summary.Value(tag="train_accuracy", simple_value=acc)]) return acc, loss, summary if __name__ == '__main__': x = tf.placeholder(tf.float32,[None, image_size, image_size, 3]) y_ = tf.placeholder(tf.float32, [None, class_num]) keep_prob = tf.placeholder(tf.float32) train_flag = tf.placeholder(tf.bool) learning_rate = tf.placeholder(tf.float32) output = vgg_net(x, weights, biases, keep_prob) correct_prediction = tf.equal(tf.argmax(output, 1), tf.argmax(y_, 1)) accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) with tf.name_scope('loss'): cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(labels=y_, logits=output)) l2 = tf.add_n([tf.nn.l2_loss(var) for var in tf.trainable_variables()]) with tf.name_scope('train_op'): train_step = tf.train.AdamOptimizer(learning_rate, beta1=0.9, beta2=0.999, epsilon=1e-8).minimize(cross_entropy + l2 * weight_decay) #train_step = tf.train.MomentumOptimizer(learning_rate, momentum_rate, use_nesterov=True).minimize(cross_entropy + l2 * weight_decay) saver = tf.train.Saver() TIMESTAMP = "{0:%Y-%m-%dT%H-%M-%S/}".format(datetime.now()) log_save_path_now = log_save_path+'/'+TIMESTAMP with tf.Session() as sess: sess.run(tf.global_variables_initializer()) summary_writer = tf.summary.FileWriter(log_save_path_now,sess.graph) alpha = 0.001 for ep in range(1, 41): start_time = time.time() print("========================epcho: %d============================="%ep) train_acc, train_loss, train_summary = train_epcho(sess, ep) val_acc, val_loss, test_summary = run_test(sess) print("epcho: %d, cost_time: %ds, train_loss: %.4f, train_acc: %.4f, test_loss: %.4f, test_acc: %.4f" % (ep, int(time.time()-start_time), train_loss, train_acc, val_loss, val_acc)) if train_acc>0.97 and train_acc=0.993 and train_acc=0.996 : alpha = 0.000001 summary_writer.add_summary(train_summary, ep) summary_writer.add_summary(test_summary, ep) summary_writer.flush() print("finish!") save_path = saver.save(sess, model_save_path) print("Model saved in file: %s" % save_path)训练结果 未采用数据增强策略之前,红色和灰色是添加了BN和dropout的结果,蓝色曲线是去掉BN和dropout的训练曲线,可以看到去掉BN收敛速度变慢了,去掉dropout和BN之后,过拟合的程度更高,在测试集上的精度下降了5个百分点。 第一次完整实现较大的任务。过程中总有意想不到的问题发生。这里做个总结,希望大家可以不要犯和我一样的错误吧。 W参数初始化。起初我采取了上次MNIST任务随机正则化初始的策略,stddev=0.5 ,事实上这是一个很糟糕的初始化策略,初始的W设置的过大,开始学习之后参数值基本不会发生变化。后边采取了tf.keras.initializers.he_normal()的初始化方法,这个方法设置如下stddev = sqrt(2 / fan_in),fan_in是输入张量的个数。 tf.nn.softmax_cross_entropy_with_logits_v2(labels=y_, logits=output) 这个函数的实现两步任务:第一步是先对网络最后一层的输出做一个softmax,第二步是softmax的输出向量[Y1,Y2,Y3…]和样本的实际标签做一个交叉熵。 第一次在实现的时候我在VGG网络中定义了softmax部分,输出output就是softmax输出的结果,然后又采用了tf.nn.softmax_cross_entropy_with_logits_v2的方式来计算交叉熵,结果精度到达0.65左右就不在提升了。关于tf.nn.softmax_cross_entropy_with_logits_v2实现的内参考这个文章。 数据增强。采用了随机翻转和随机平移两种策略来进行数据增强,采用数据增强后train_loss收敛速度变慢,但测试集上的效果有了明显的提升。 学习率的问题。采用adam算法后train_loss很快就可以收敛到一个不错的值,此时精度变化将很小,将学习率调整到一个较小的值之后,梯度下降可以朝着一个更加精确的方向前进,test_loss指标也有了很大的提升,这点在tensorboard的训练图像中表现的很明显。adam算法可以参考这篇博客。 这次采用VGG网络实现cifar10分类任务测试集上最终的精度大约在0.92,epcho=40,训练时长为50分钟左右。相较于别人采用VGG实现的精度还有一点差距,最终的train_loss还在提升,精度也略有提升,后续可以继续增加训练次数来提升效果(对比https://github.com/kuangliu/pytorch-cifar),本文的许多方案和代码来自于https://blog.csdn.net/GOGO_YAO/article/details/80348200。 |



 采用了数据增强策略后,train_loss收敛速度变慢,但最终测试集上的精度有了较大的提升。
采用了数据增强策略后,train_loss收敛速度变慢,但最终测试集上的精度有了较大的提升。 

【本文地址】
今日新闻 |
推荐新闻 |